Function Review and Tips
- Doug Bates
- Apr 7, 2023
- 6 min read

Purpose
Looking back after completing three recent projects, I ended up using 60 functions, including several new ones that I initially doubted I would ever use. I grew more accustomed to using AFE (Advanced Formula Environment), not only for ease of writing formulas but also as an organizational tool. Today I'll review and recap what I've learned, give updates on some custom functions, and give an overview of conditional and branching functions.
Functions, Formulas, AFE
LAMBDA has blurred the distinction between function and formula. It used to be simple: functions come with Excel and accept arguments; formulas are written in cells using inputs, functions and operators. Custom functions that accept arguments could only be written in VBA. With LAMBDA we can now write VBA-less formulas that accept arguments. Then should we call these formulas or functions?
Native Excel functions and VBA functions are categorized and listed in the Insert Function picker, Shift+F3, LAMBDAs are not. LAMBDAs can be called functions because they accept arguments, but must be known, or browsed by in-cell type-ahead. Once you type = in a cell followed by any letter, you get a list of native functions, as well as LAMBDAs and all other names found in Name Manager:
=a all functions and names beginning with "a"
=my all functions and names beginning with "my"
=cal all functions and names containing "cal"

In the end, semantics don't matter much, certainly if you only write LAMBDAs for your own use. Here's a simple way to think about it: using the in-cell pick list, the square range icon may be a range, a constant or a formula without arguments; the circle fx icon is a "function" - with arguments.
Using a naming convention can also help keep track of names by purpose. In particular, AFE modules prefix the name, acting as a mnemonic category. I stick to one or two letter module names, like d for dates, i for internal or cf for conditional formatting. Names created outside of a module can be manually prefixed.
One lesson learned is that LAMBDA can easily lead to high complexity workbooks. That's a good thing, as it expands potential, and a risk. AFE and modules mitigate workbook complexity; LET and comments mitigate formula complexity; all mitigate developer frustration and insanity.
AFE has built on long-standing Name Manager value and proven its use as a formula factory and warehouse.
Design Considerations
Why Use LAMBDA?
Starting from the workbook purpose it must be clear what the output objectives are. From there we determine what inputs must be given to achieve that output. If we then draw an imaginary line from input to output, this represents the ideal shortest path. But is it a traditional formula or a LAMBDA?
To take an example, we want to calculate the hypotenuse of a right triangle. We need to supply two inputs, i.e. the two perpendicular sides which we'll call A1 and B1. We can do this simply with the two input cells and one output cell in which we put the formula:
=SQRT(A1^2+B1^2)
If that's it, that's all. But if we later need to use the same formula elsewhere, we need to copy or repeat the process. Every repetition adds risk of error and waste of time. Frequency of use, either immediate or possible use, is an important driver of LAMBDA.
If we write the same formula as a LAMBDA,
hypotenuse= LAMBDA(a, b, SQRT(a ^ 2 + b ^ 2))
Then the logic is written once, eliminating duplication risk and cost. Of course, the more complex the formula and the more frequently used, the greater the benefit. The point is that LAMBDA is a powerful tool that should be used intentionally.
Formulas Without Arguments
If the formula is unique and arguments are not needed then duplication is not an issue, and there's no benefit to using LAMBDA. Then what of argument-less formulas, should they be written in the sheet, or "canned" in AFE and called in the sheet? It probably depends on the purpose and the audience.
If the sheet uses table or array structure, you can minimize the cells to edit and audit - in a table, by column formulas; in an array, by the top-left cell. This reduces risk but remains awkward. On the surface, you don't know how many formulas there are unless you format them or use F5 to select them, and you don't know how complex they are until you go through them one by one. The more complex they are, the more benefit you'll get from naming them. When the sheet only calls named formulas, you have effectively removed risk to the formula repository, where it can more effectively be understood and controlled.
I regularly have my second monitor split in half, the sheet on the left and AFE on the right. When AFE is governing all the formulas, this becomes an intuitive development platform: on the right, technical structure; on the left, validation and output design.
Arguments vs. Preferences
Arguments should be limited to variables that a user is likely to change depending on their purpose, and made optional when possible, with default values defined. A default value gives the user a starting point from which to experiment and learn.
Preferences are variables that are most likely to be set once and never changed. If all such variables were run-time arguments, the list could get very crowded and confusing. It's best to handle these outside of the argument list. Especially when designing for a global audience, consider a diverse-user-friendly way to manage such settings. Below are three options.
Function Code
Array Constant
Control Sheet with Named Settings Cells
My LAMBDA Updates
Here are updates of some functions that I've previously published, and a few new ones.
a.shift: shift array any direction
d.profile: hybrid date period profile
d.workdays: workday date list or count by month
d.calendar output: perpetual, month stack or annual calendar
d.calendar formulas
cf module: conditional format conditions
a.myannuals and d.annuals: birthdays and anniversaries
"-IF-" and "IS-" Functions
SUM, AVERAGE, COUNT
Three functions, SUM, AVERAGE and COUNT each have -IF and -IFS versions for use with one or multiple criteria. Conditional SUM and AVERAGE functions work the same way: criteria can be applied to the same numeric range that is being operated upon, or to a different range, which can be text or numeric.
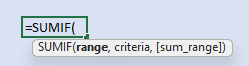
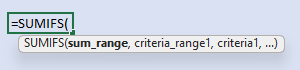
There is what seems to be an inconsistency in the order of arguments in the jump from one to many criteria, but the rationale is understandable. SUMIF requires range and criteria followed by optional sum range. SUMIFS puts sum range first, followed by an indefinite number of criteria range-value pairs. The way that sum range moves from last in SUMIF to first in SUMIFS is an unfortunate effect, but one that we can easily get over by remembering this explanation.
There's a simple way to avoid confusion on the order of input ranges, by ignoring SUMIF and just use SUMIFS. However, when the sum range IS the criteria range, SUMIFS requires the range twice, SUMIF only once. Keep that in mind as you make your choice.
COUNTIF/COUNTIFS are indifferent to the data type in the range (as long as the criteria match the type), and therefore don't have the same "roaming range" effect as the conditional SUM and AVERAGE; with conditional COUNT, range is always criteria range.

MINIFS and MAXIFS work like SUMIFS, but do not have singular versions.
All Functions Containing "IF"
=IF(logical_test, [value_if_true], [value_if_false])
=IFS(logical_test1, value_if_true1, [logical_test2, value_if_true2], ...)
=SUMIF(range, criteria, [sum_range])
=SUMIFS(sum_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...)
=AVERAGEIF(range, criteria, [average_range])
=AVERAGEIFS(average_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...)
=COUNTIF(range, criteria)
=COUNTIF(criteria_range1, criteria1, [criteria_range2, criteria2], ...)
=MINIFS(min_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...)
=MAXIFS(max_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...)
=IFNA(value, value_if_na)
=IFERROR(value, value_if_error)
Boolean Evaluations
Complementing conditional output functions are a set of functions that evaluate Boolean input conditions. These can be used to control output and handle errors.
Functions beginning with "IS"
=ISBLANK(reference)
=ISERR(reference)
=ISERROR(reference)
=ISEVEN(reference)
=ISFORMULA(reference)
=ISLOGICAL(reference)
=ISNA(reference)
=ISNONTEXT(reference)
=ISNUMBER(reference)
=ISODD(reference)
=ISREF(reference)
=ISTEXT(reference)
Below are shown some shortcut ways to evaluate input as true or false, including x, N(x) and LEN(x).
Branching Functions
Below are shown several ways to branch or select among multiple outputs.

IF: as long as x is numeric it can be used as a condition - any non-zero is TRUE
IF: if x is text it has no Boolean condition
IF: N(x) text is FALSE, numbers are TRUE
IF: LEN(x) blank is FALSE, non-blank are TRUE (same as NOT(ISBLANK(x))
IF: nested IF example
IFS: arguments in "condition/if true" pairs; first hit wins; to set a default, use TRUE as final condition
CHOOSE: x must be between 1 and the number of outputs
CHOOSE: error if x > number of outputs
CHOOSE: with error handling to force range
CHOOSE: with SIGN(x)+2
CHOOSE: with XMATCH of x to an array
SWITCH: single condition - "condition/if true" pairs - default output
Comments