Part 2: Export/Import, Uniqueness, Governance, Reverse Concatenated Array Lookups!
- Doug Bates

- Mar 17, 2023
- 5 min read
spoiler alert: conclusion and special offer coming next week...

"Clean data in, clean data out" is my positive spin on the familiar GIGO maxim. It means that attention to data integrity belongs at the source. The further downstream errors are found, the more costly they are to correct and in their effect. With a data transfer process, the costs further multiply with the risks of handling errors, dual maintenance and refresh.
In this second installment of the Bloodline Project, we'll look at the sourcing and grooming of the data with the objectives of ensuring data integrity and reformatting the data to output requirements. In addition, maintainability is an implicit need. Since the data are maintained externally, the export/import and grooming process will be repeated periodically and must be documented.
The Data Source
Genealogical data are managed by software such as Family Tree Maker (FTM). Ancestry.com can also maintain the tree but cannot export to Excel. The tree can be synchronized with FTM or transferred to any genealogy program via GEDCOM file and exported from there.
FTM data are downloaded to Excel by export of a custom report to CSV format (comma-separated values). Other programs likely have similar features. The Source sheet gives detailed instructions to download from FTM to Excel. Using a sheet like this to document the process is an element of transparency and elegant design.


The Import Table
The raw data are copied from the exported .csv file to the first eleven columns of the Import table, then checked and maintained as needed to ensure a clean table: no old data left behind, no blank rows. The rest of the table is calculated, indicated by vertical borders separating column groups, and by gray fill on the condition ISFORMULA. This helps delineate raw from processed columns, and shows if any formula cells are accidentally deleted.
The data are processed in three main groups: names, dates and places; a fourth group comprises year of birth and death which are used internally. The formulas are written in AFE module i for convenience and security (see earlier posts about AFE and LAMBDA).
Birth and Death Year
The purpose of these internal columns is to index duplicate names according to dates to make them unique. The method used is not ideal, but acceptable with a caveat. There's a small risk of the index changing if the table is sorted. Since this table is for import processing and not output, there's no need for sorting. The risks are mitigated with warning messages.
Historical dates have many forms.
Dates from 1900 import as date values with cell format beginning with D
Dates before 1900 import as text ending with 4-digit year (or 7, see below)
Dates entered as year only import as number with cell format G
Dates entered with "Abt" or "Bef" etc. are text ending in year
Dates may be "unknown" or blank
These diverse conditions must each be handled to output a reliable year number.
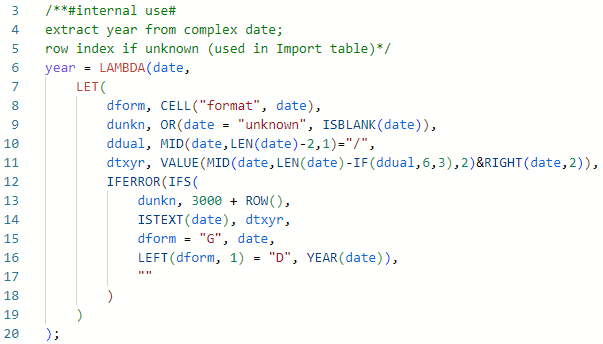
Notes
ddual and dtxyr in row 10-11 account for double dates due to the transition from Julian to Gregorian calendar, e.g. 1721/22
in row 13 unknown dates are indexed by 3000+ROW(). This makes it obvious that those rows have unknown or blank dates. Use of row number could change the resulting index if the table is sorted, as noted above.
years>3000 look weird, but again this table is internal; if the years were used in output they would be filtered out.

This is then used in two columns for birth year and death year.
Names
The name column group transforms each of the four import names, Name, Father name, Mother name, Spouse name, to make them unique. Note that every row has a Name, not every row has the other three names. However, every Father, Mother and Spouse name also exists in the Name column. Further, every Name/Spouse pair exists twice, as husband/wife and wife/husband; every Father/Mother and Mother/Father pair exists as a Name/Spouse pair. These combinations will be used to advantage. The key is first to make Name unique, then apply it to the other columns.
UName
To illustrate the logic here's a demonstration, with two temporary columns added:
test1 is each row's concatenated [@BYear]&[@DYear]
test2 is a string of all the test1 values for each name
The first duplicate name is Abigail Adams of which there are three, numbered 1 to 3 by the position of their test1 value in the test2 string.

This logic is performed within the formula:

Assess Uniqueness
With such pains taken to generate a unique name key, and with a view to the uncertain state of future data, a uniqueness check will play an important role in project integrity. First, how many names are shared with at least one other person? As a short sidetrack, here are three ways to answer the question:
Conditional Format for Duplicates
1. Select the Name column

As reminder, to select all data rows in a table column, place the mouse cursor over the header and raise it until the down-arrow selector appears. The cursor should be on the top border of the header cell.
2. Set Conditional Format

Home - Conditional Formatting - Highlight Cells Rules - Duplicate Values, and accept the default light red fill format.
3. Filter [Name] by the duplicate fill color

Count Column

A more detailed way is to add a column, ct =COUNTIF([Name],[@Name]). This counts the current row's name within the entire name column. We can then use the filter button to see the range of values, and filter out names that are already unique, that is, whose count = 1.
Frequency Table
Another level of analysis is a frequency table or histogram. This is not necessary, but interesting and easy. Here's an example for the count column FTM[ct]:

AL2: =SORT(UNIQUE(FTM[ct]))
AM2: =FREQUENCY(FTM[ct],AL2#)
AN2: =AM2#/SUM(AM2#)
AO2: =IFNA(AM2#/AL2#,0)
AP2: =AO2#/SUM(AO2#)
Once we understand a problem, we need to solve it. Even if we manage to build a unique key, there's no guarantee it will be unique every time we import new data. The solution then is not only a clever formula but built-in governance with stop-and-fix guidance.
"About" Sheet
A good practice in general is to provide an "About" sheet. Here you can give general information, support contact, user preferences and data status check. The four default settings on this sheet are used below in date and place field formatting.

Statistics are given for Import and Ancestors tables. Unique Import counts are calculated like =ROWS(UNIQUE(Import[Name])). Known Ancestors counts are calculated like =COUNTIFS(Ancestors[Gen],gen,Ancestors[known],TRUE). When UName has any duplicates, the sheet appearance alerts and instructs the user:

In addition, the Import table itself flags the duplicate condition in red font.

If there are duplicates in UName it means that two rows have the same name, birth year and death year. That's highly unlikely in reality, but accidental duplication in genealogy in not uncommon. FTM has editing tools to find and manage duplicates. If they show up in Excel they should be deleted from the table.
USpouse
Now that we have a unique name, we can use it to uniquify the other three names. Here we use some array magic: lookup this Name&Spouse in all Spouse&Name, and return UName. If there's no Spouse this copies Name, hence we check first for Spouse.

UFather and UMother
If Father and Mother are both known (fact * moct), then Father looks up this Father&Mother in all Name&Spouse to get UName, likewise Mother looks up this Mother&Father in all Name&Spouse to get UName. If only one parent is known and their Name is already unique, copy it, else blank.

Dates
The three date fields use one formula. Note there are no table references since the field is given as a function argument, e.g. =i.dateconvert([@[Birth Date]]). [format] is an optional argument, with the default set on the About sheet seen above.
As noted about, with historical dates that span the year 1900 we must account for a variety of input types. Dates from 1900 are simply converted by TEXT with the desired format string. With dates before 1900 I use an offset to make them Excel-compatible. I've shown this method before in the LAMBDA template.
dissect the text date to separate day and month from year
DATEVALUE of the day and month in year+2000
TEXT of the offset date in desired day/month format, e.g. "dd mmm "
re-attach the original year
Other conditions are handled as required.

Places
Like dates, three place fields use one formula with the respective argument. Here there are three optional arguments for which defaults are set on the About sheet. There are three manipulation objectives:
replace the existing jurisdiction delimiter with a new one
substitute state abbreviation for state name
ignore country name at end (e.g. USA)

Note the name states above is a named array:

A list of states and abbreviations can easily be found and copied from the internet. Here's a trick to create a named array without typing:
copy/paste the list to Excel as text only
in a nearby cell, enter =ARRAYTOTEXT(array,1), where array is the list range (e.g. 50 rows x 2 columns)
before hitting Enter, hit F9 to calculate the formula, and hit Ctrl+C to copy
create the name and in Definition, type = and paste the copied text
This is good practice to store any static lookup array as a name rather than on a sheet.


Comments